Basic Rules of Data Modeling in GoodData
Version Compatibility Notice
The content of this article is valid for the version of GoodData that was current as of 19 October 2020. Features or behavior in newer versions may differ.
We are continuing our series of articles about the Logical Data Model in GoodData. In this article, you will learn the basic rules for creating a viable Logical Data Model in GoodData.
If you have not done it yet, you should also read the previous articles in this series, starting with Logical Data Model - Introduction and continue to Logical Data Model - Objects of the Logical Data Model.
Modeling data in GoodData is easy, you just need to follow five simple rules:
- Model based on your reporting requirements
- You can filter and slice against the direction of the arrows
- If an Attribute in the same role belongs into multiple datasets, make it a shared dataset
- References are mandatory
- Do not create multiple paths between datasets
Let’s discuss each of these rules now:
1. Model based on your reporting requirements
Before jumping into the modeling, you should know your data and have an idea about what kinds of reports you want to build on top of it. We are not referring to whether you will use bar charts or pie charts, but rather what values (measures) you want to display, by what you want to display them, and how you want to filter. There is no need to go into exact detail and describe every single insight, but use the entities (i.e., I want to be able to see orders by customer, sales date, and shipment date).
Sometimes, this approach is called Dimensional Modeling.
2. You can filter and slice against the direction of arrows
When you are looking at the LDM in GoodData, the direction of the arrows (references) is very important. When building the metrics and insights later on, you will be able to filter by anything which is either in the same dataset OR in a dataset which is connected against the direction of the arrow.
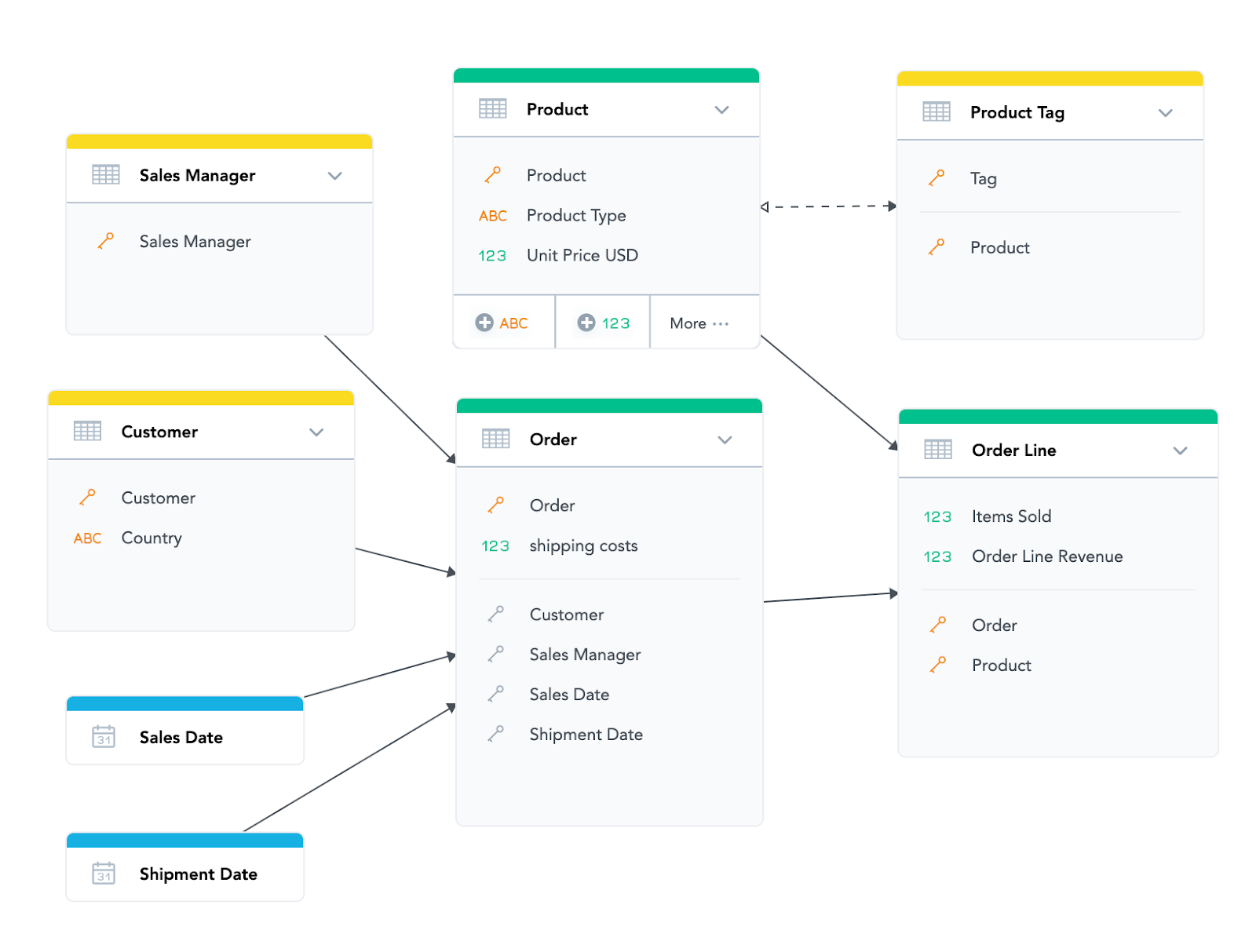
In our sample model above, you will be able to aggregate “Items Sold” by any of the attributes in the data model. That is because “Product” is in the dataset Product, which is against the direction of the arrow from “Order Line” where “Items Sold” exists.
Also, all the other attributes (including both date dimensions) are connected to the “Order Line” and we can get to them from there by moving against the direction of the arrow. Even the “Tag” is connected against the direction of the arrow (because the M:N arrow between “Product” and “Product Tag” is bi-directional).
On the other hand, the “Shipping costs” which exist in the “Order” dataset will NOT be possible to filter by “Product” or “Product Type” or “Tag”. That is because while the dataset “Product” is somehow (through Order Line) connected to “Order”, we cannot get there by going against the direction of the arrow.
It also does not make sense logically because the shipping cost in our example is associated with the whole order, and an order can consist of multiple different products. (Note—there are ways in MAQL to make an advanced calculation that allows you to allocate part of the shipping costs to each of the Order Lines, but let’s not complicate things for now.)
So, create your Logical Data Models in a way that allows you to filter and slice the values as you want in your insights and dashboards.
3. If the same Attribute belongs into multiple datasets, make a shared dataset for it
This rule means that if you want to use some attribute (or group of attributes) to filter or slice more than one dataset, you need to create a shared dataset that will be referenced by them.
For example, if we want to add information about the sales quota for each Sales Manager, we reuse the existing “Sales Manager” attribute. It is already in its own dataset, so it is easy to connect it to the new “Sales Quota” dataset. And it works the same way with dates. We want to have a monthly sales quota for each Sales Manager - the quota will be evaluated by sales date, so we connect the existing “Sales Date” to “Sales Quota”:
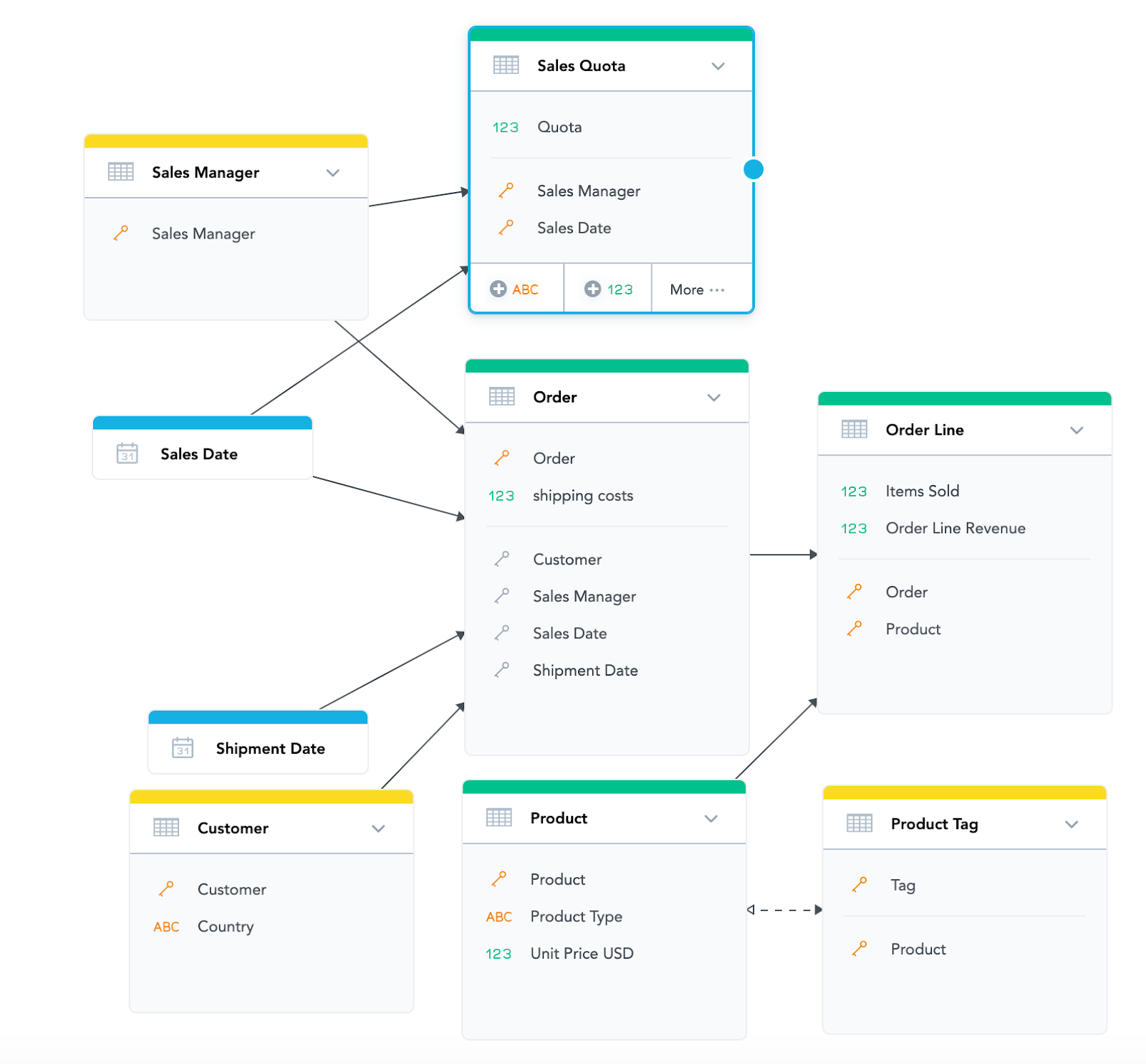
Now, because “Sales Quota” (directly) and “Order Line” (via Order) are both connected to “Sales Manager” and “Sales Date”, we will be able to compare the revenue each Sales Manager achieved in a given month with his quota for that month.
4. References are mandatory
Keep in mind that in GoodData, if there is a reference, it is mandatory. In our example, when we have a reference to “Sales Manager” in the “Order” dataset (meaning the person who made the sale), each order needs to have exactly one value of Sales Manager, and this value needs to exist in the Sales Manager dataset. This does not mean that each Sales Manager needs to have some order though.
If a Sales Manager was not mandatory for an Order and some deals were not assigned one, an artificial record, i.e., “(no sales manager),” would need to be added to the Sales Manager dataset.
5. Do not create multiple different paths between datasets
In GoodData, each reference needs to be unambiguous, so avoid references that can create ambiguity. For instance, in the following example, we wanted to capture a business decision to assign each “Product” a dedicated Sales Manager who “owns” it.
But with this setup, there are two possible ways the “Order Line” is connected to “Sales Manager”, and each means something different:
- The first is the original one - who sold this particular order
- The second is now the “owner” of the product that was sold (no matter who sold it)
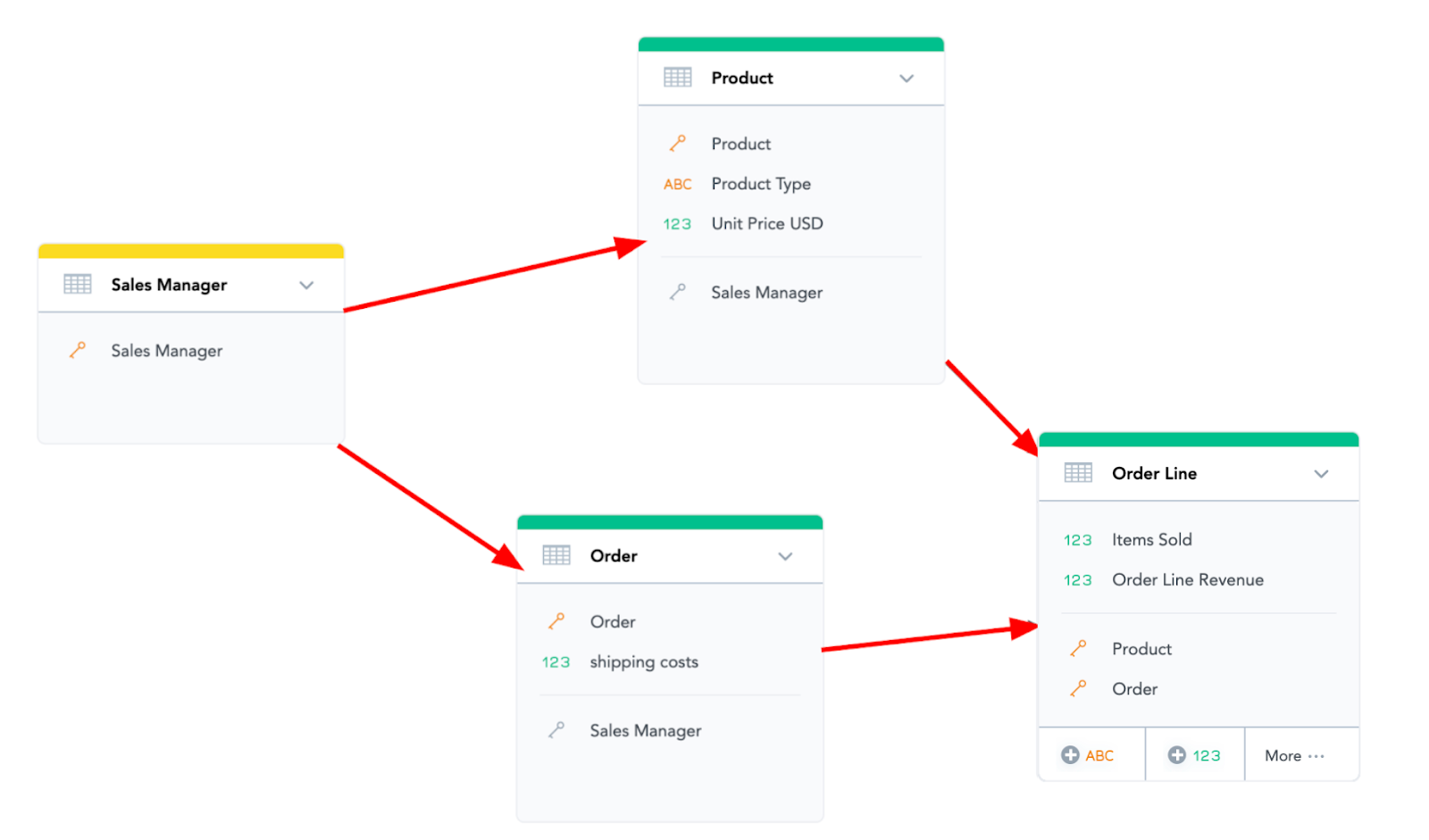
So this is NOT the correct way to model things in GoodData. If done in this way, you may get incorrect or unexpected results because GoodData expects all the paths to have the same meaning.
If we want to capture both roles the Sales Manager can have, we need to use a different approach. For example, the one where we will have a separate attribute for the Sales Manager who sold the order and the one who owns the Product.
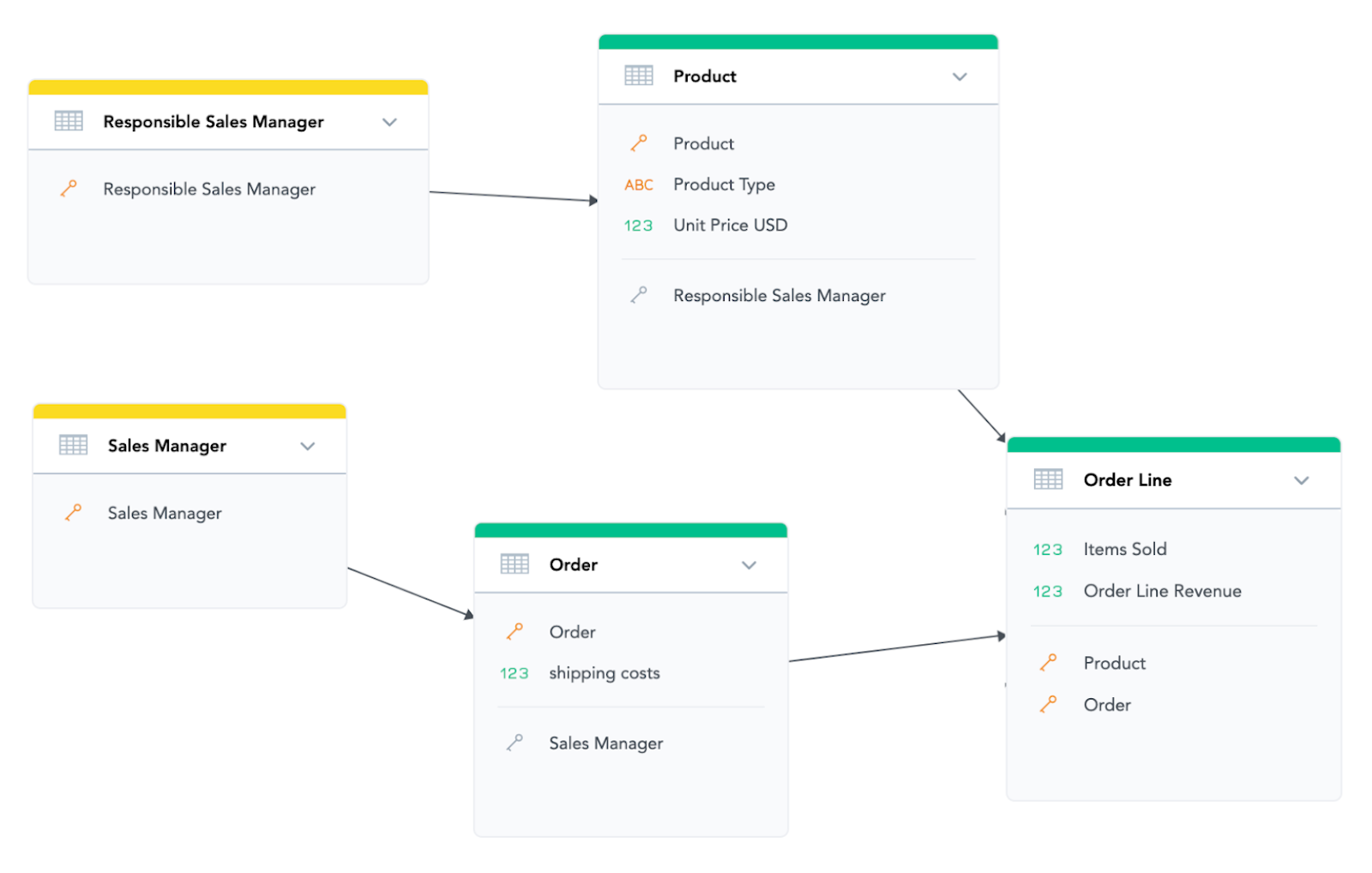
That’s it. If you follow these simple five rules, your data models will work as a charm and you will unlock a lot of possibilities for ad-hoc reporting both for you and your customers.
Next article in this series is: Logical Data Model - Five Pro-Tips for Data Modelling
Let us know how you like this series and feel free to post questions if something is not clear to you. For more information and practice about data modelling, please also attend our free courses at GoodData university.