Designing Data Models
Introduction
Data Models and the Semantic Layer
Businesses generate a lot of data that needs proper analysis for decision-making. This data comes from various sources and formats, making it hard to understand. The semantic layer helps with this.
The semantic layer sits between the database and the user applications. It simplifies and standardizes data views for users, hiding the complexity of the data sources. It maps physical data to a conceptual model, defining rules and relationships and providing a common business vocabulary. This allows users to interact with data easily without technical knowledge.
In GoodData, everything connects to a semantic layer, which turns complex data into business-friendly terms. A good semantic model ensures that information is shared and understood consistently. Without it, users would only have raw database tables or JSON files.
The core of the semantic layer is the Logical Data Model (LDM). This course will teach you to build data models that are:
- Easy to manage
- Scalable
- Cost-effective
We’ll start with simple models and guide you through important decisions in data modeling, such as organizing data and defining structures, constraints, and operations.
Data modeling is creative and allows you to shape the data experience for users and machines. You’ll define what is allowed, forbidden, mandatory, or optional, and the easiest operations to perform.
All Models Are Wrong
Data modeling is a stimulating discipline because there is never just one correct way to build a data model. In fact, all models, including data models, are biased by definition. Models distort reality, hide complexities, and omit details, but in doing so, they also help us better understand reality and focus on the important. Instead, the quality we search for in models (and in data models especially) is not how correct they are but how useful they are.
Why Data Modeling for Analytics
Operational databases—like your system of records for orders, sales opportunities, or a CMS—typically allow people to enter new data. The model is optimized for quick, granular read-and-write operations, like displaying an order, updating an opportunity, or creating a new article. The data model conforms to a normalized relational schema to ensure data integrity. Usually, it is in the third normal form (3NF). You may also see schemaless (NoSQL) data models that allow for great flexibility and unanticipated changes.
This course will use a 3NF data model as an example of our source data.
Analytical Model
In the world of analytics, we start with data already stored and modeled. However, this operational, normalized model is not helpful for analytics because it forces us to write analytical queries that are far more complex and less efficient than we want. As a result, database performance suffers, business users cannot write queries themselves, and data security needs to be manually set per query or per level of aggregation. It is a lose-lose situation. Instead, we need to transform the model into a new analytical model.
Why It Is Easy
Data modeling for analytics is an easy discipline to learn for two main reasons. We do not need to start from scratch because our source data is already modeled. Whatever data model we create can only work with existing data and existing relationships, which streamlines data modeling. We modify and transform the existing data and relationships.
The second is that there are only a few simple rules to follow. The most common schema suitable for analytics is called a star schema. The simplest models look like a star: one table in the center of the star (a fact table) and several other tables (dimensions) around it. Each dimension has a single primary key and is connected to the fact table, including the foreign key. Dimensions are not linked to each other.
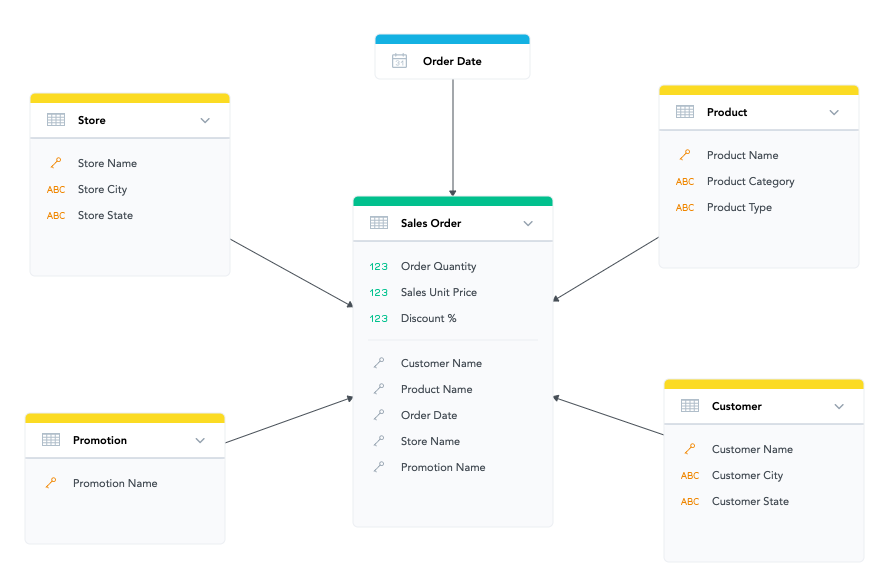
This means the data structure will always look the same for any business use case. When you want to include a column from a dimension and a column from the fact table in the same query, there is always only one way to join the two tables. When you want to add a column from a different dimension, there is only one way to build the query. A star with five dimensions will always have precisely five connections, and the fact table will always have five foreign keys. In this course, a data model for analytics will always refer to a model consisting of one or more stars, which we call a dimensional model.
Why It Is Hard
Every data model is a simplification. There will always be objects and relationships that exist or are true but are not reflected in your model. However, the art of dimensional data modeling is correctly choosing what to keep and omit.
In creating a data model, we are driven by the business questions we want to answer (requirements) and limited by source data. The challenge is to build a model optimized but not over-optimized for the business requirements. An over-optimized model supports the current business requirements very efficiently; the queries are easy to write and perform well. However, the model does not anticipate new requirements, so every change and every new query would need massive, complex data reorganization. Instead, the most helpful data models support the current requirements well and anticipate changes.
Data Models in GoodData
When building a model, you will create an LDM that consists of datasets. In GoodData Cloud, datasets are mapped directly to database tables. GoodData works with a semantic layer in both data modeling and building insights. The semantic layer uses business terminology—a catalog of words and phrases that have shared and governed meaning—and allows for quick and reusable query building. The semantic layer empowers business users to build insights and answer business questions. Depending on the context, the insights are automatically translated into SQL queries executed on the physical schema. You do not specify column names or join tables.
What to Expect
There are a few things to keep in mind regarding data models and the way we discuss them in this course:
- We will discuss only data models suitable for data analytics. Different rules would guide other data models (e.g., normalization).
- We will lead you toward the best designs with GoodData’s analytical engine. The engine’s power simplifies both the insight-building experience and the LDM design.
In the next lesson, we introduce the source data we will work with during this course. Then, we start asking questions that the data can answer. Each question introduces new modeling concepts.